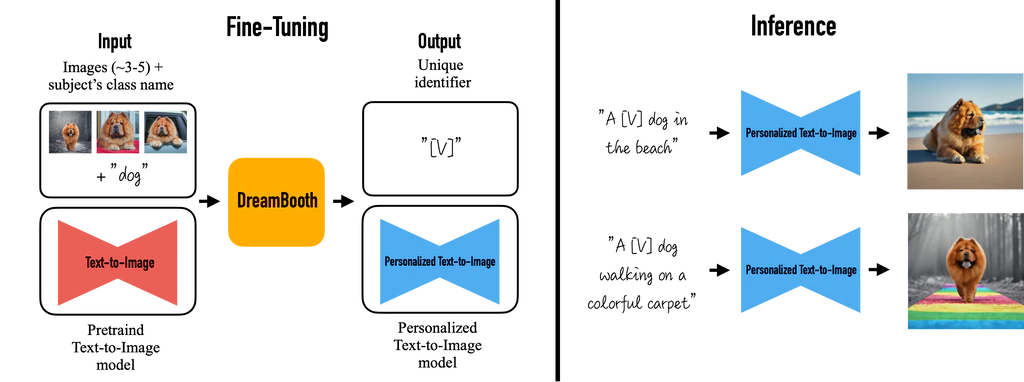
DreamBooth
Améliore les modèles de diffusion text-to-image pour une génération axée sur un objet ou une personne.
La recherche en intelligence artificielle Dreambooth a été réalisé par des chercheurs de chez Google.
– Nataniel Ruiz
– Yuanzhen Li
– Varun Jampani
– Yael Pritch
– Michael rubinstein
– Kfir Aberman
Dreambooth est comme un comme un photomaton, mais une fois l’objet ou la personne connue, il peut synthétiser là où votre imagination vous mènent…

Explications
Les modèles text-to-image ont réalisé un bond remarquable dans l’évolution de l’intelligence artificielle, permettant une synthèse d’images diversifiée et de haute qualité à partir d’un texte donnée.
Cependant, ces modèles n’ont pas la capacité d’imiter l’apparence des sujets dans un ensemble de référence donné et d’en synthétiser de nouvelles interprétations dans différents contextes.
Dans ce travail, Dreambooth présente une nouvelle approche de « personnalisation » des modèles de diffusion text-to-image (en les spécialisant aux besoins des utilisateurs).
En entrée, seulement quelques images d’un sujet, nous affinons un modèle text-to-image pré-formé de sorte qu’il apprenne à lier un lien unique avec le sujet.
Une fois que le sujet est intégré dans le domaine de sortie du modèle, le lien unique peut ensuite être utilisé pour synthétiser des images photoréalistes du sujet contextualisées dans différentes scènes.
En tirant parti de l’a priori sémantique intégré dans le modèle avec une nouvelle perte de préservation a priori spécifique à la classe autogène, Dreambooth permet de synthétiser le sujet dans diverses scènes, poses, vues et conditions d’éclairage qui n’apparaissent pas dans les images de référence. Nous appliquons notre technique à plusieurs tâches auparavant inattaquables, notamment la re-contextualisation du sujet, la synthèse de vues guidée par le texte, la modification de l’apparence et le rendu artistique (tout en préservant les caractéristiques clés du sujet).
Découverte

Comme dans l’exemple, l’horloge, il est aujourd’hui très difficile de le générer dans différents contextes avec des modèles text-to-image de pointe, tout en conservant une haute fidélité à sa clé caractéristiques visuelles.
Même avec des dizaines d’itérations sur une invite de texte contenant une description détaillée de l’apparence de l’horloge (« réveil jaune de style rétro avec un cadran blanc et un numéro trois jaune sur la partie droite du cadran dans la jungle »), le modèle Imagen ne parvient pas à reconstituer ses principales caractéristiques visuelles (troisième colonne).
De plus, même les modèles dont l’incorporation de texte se situe dans un espace de vision du langage partagé et peuvent créer des variations sémantiques de l’image, comme DALL-E2, ne peuvent ni reconstruire l’apparence du sujet donné ni modifier le contexte (deuxième colonne).
En revanche, Dreambooth (à droite) peut synthétiser l’horloge avec une haute fidélité et dans de nouveaux contextes.
Approche
Dreambooth prend en entrée quelques images d’un sujet (par exemple, un chien spécifique) et le nom de la classe correspondante (par exemple, « chien »), et renvoie un modèle text-to-image « personnalisé » qui encode un identifiant unique qui fait référence au sujet. Ensuite, lors de l’inférence, nous pouvons implanter l’identifiant unique dans différentes phrases pour synthétiser les sujets dans différents contextes.
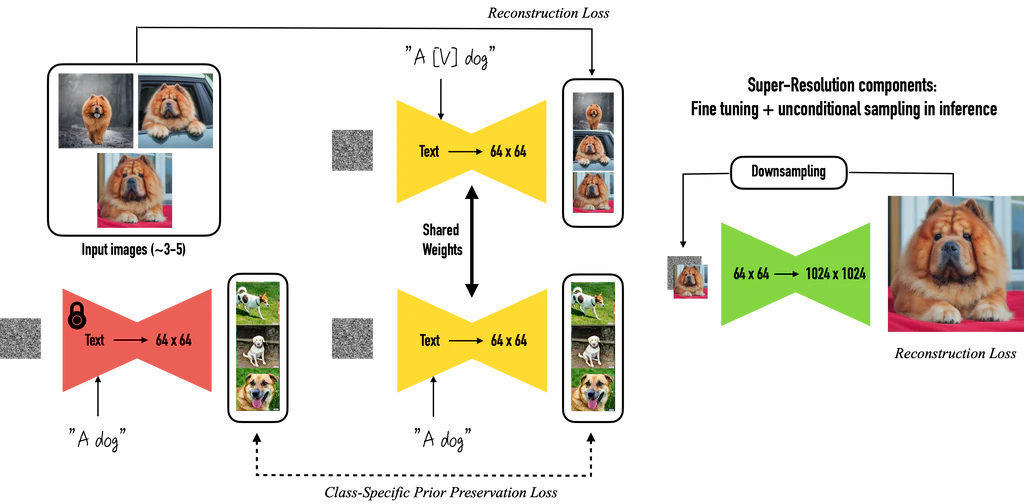
Étant donné les images d’un sujet, Dreambooth crée une diffusion text-to-image en deux étapes :
– Affiner le modèle text-to-image basse résolution avec les images d’entrée associées à une invite de texte contenant un unique identifiant et le nom de la classe à laquelle appartient le sujet (par exemple, « Une photo d’un chien [T] »), en parallèle, nous appliquons une perte de préservation a priori spécifique à la classe, qui exploite l’a priori sémantique que le modèle a sur le classe et l’encourage à générer diverses instances appartenant à la classe du sujet en injectant le nom de la classe dans l’invite de texte (par exemple, « Une photo d’un chien »).
– Affiner les composants de super résolution avec des paires d’images basse résolution et haute résolution tirées de notre ensemble d’images d’entrée, ce qui nous permet de maintenir une haute fidélité aux petits détails du sujet.
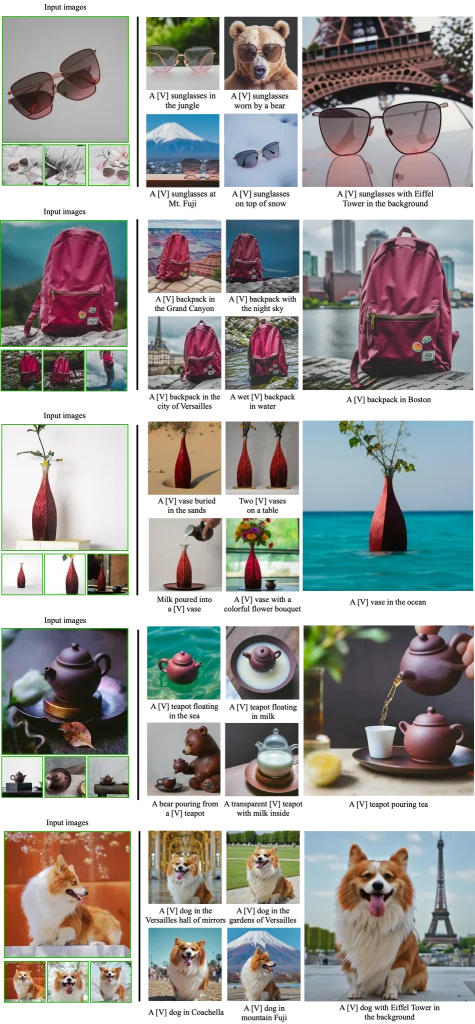
Résultats
Voici quelques exemples de résultats avec Dreambooth pour la re-contextualisation d’instances de sujet, des lunettes, un sac et un vase.
En affinant un modèle à l’aide de notre méthode, nous sommes en mesure de générer différentes images d’une instance de sujet dans différents environnements, avec une préservation élevée des détails du sujet et une interaction réaliste entre la scène et le sujet.
Nous affichons les invites de conditionnement sous chaque image.
Rendu artistique
Dreambooth peut représenter un sujet (chien par exemple) dans le style de peintres célèbres.
Dreambooth indique que certaines interprétations semblent avoir une composition nouvelle et imitent fidèlement le style du peintre – suggérant même une sorte de créativité (extrapolation compte tenu des connaissances antérieures).

Vue guidée par description
Dreambooth peut synthétiser des images avec des points de vue spécifiés pour un sujet (de gauche à droite : vues de dessus, de dessous, de côté et de dos). Notez que les poses générées sont différentes des poses d’entrée et que l’arrière-plan change de manière réaliste en cas de changement de pose. Dreambooth souligne également la préservation des motifs de fourrure complexes sur le front du chat sujet.

Modification des propriétés
Ici vous pouvez constater la modification des couleurs, et les croisements entre un chien spécifique et différents animaux. Dreambooth préserve les caractéristiques visuelles uniques qui donnent au sujet son identité ou son essence, tout en effectuant la modification de propriété requise.

Accessoires
Équiper un chien d’accessoires. L’identité du sujet est préservée et de nombreuses tenues ou accessoires différents peuvent être appliqués au chien. Avec Dreambooth il existe une grande variété d’options possibles.

Impact sociétal
Dreambooth vise à fournir aux utilisateurs un outil efficace pour synthétiser des sujets personnels (animaux, objets, personnes) dans différents contextes. Alors que les modèles généraux de texte à image peuvent être biaisés vers des attributs spécifiques lors de la synthèse d’images à partir de texte, Dreambooth permet à l’utilisateur d’obtenir une meilleure reconstruction de ses sujets.
Au contraire, des parties malveillantes pourraient essayer d’utiliser ces images pour induire les téléspectateurs en erreur. Il s’agit d’un problème courant, existant dans d’autres approches de modèles génératifs ou techniques de manipulation de contenu.
Les recherches futures sur la modélisation générative, et plus particulièrement sur les priors génératifs personnalisés, doivent continuer à étudier et à revalider ces préoccupations.
Source: https://dreambooth.github.io/